ELI5: Blockchains explained in simple terms
A blockchain is a database formed by a sequence of entries called (you guessed it) blocks.
Blockchains have a special characteristic by which any attempt to modify one of its entries would modify the entire chain.
It is, therefore, an immutable data structure, which stores blocks in chronological order of insertion.
This makes blockchain a perfect storage medium for financial records which need to be audited, such as Bitcoin transactions.
In fact, Bitcoin was the first widely adopted application of blockchains for financial record keeping.
Block Data Structure
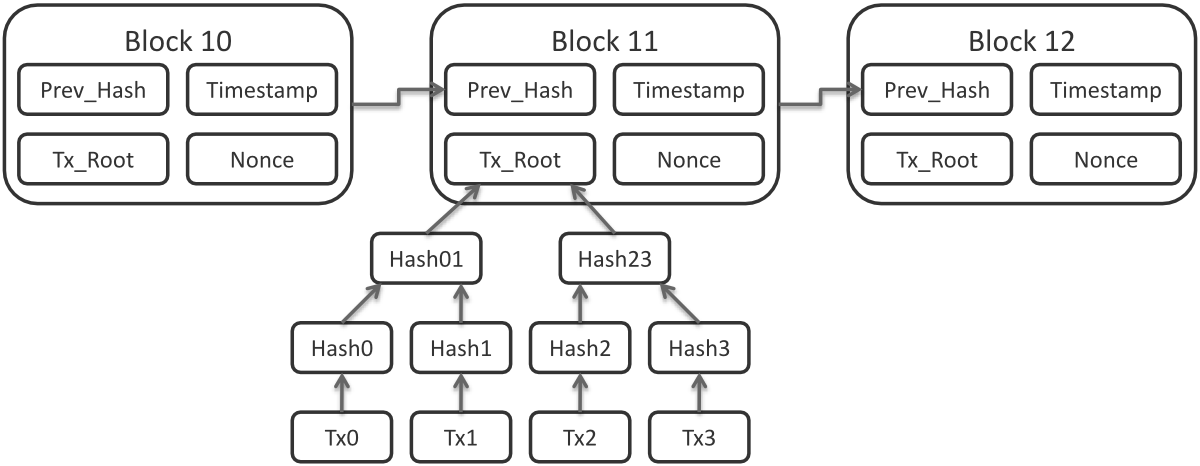
Each entry in a blockchain is called a block, which is a data structure that contains a header and a payload.
Every blockchain header must have a field that points to the block before. The link from every block to the block before forms the chain of blocks.
Genesis Block
The very first block does not have a previous entry to point to. It therefore points back at nothing, which makes it a unique entry. It’s the only block whose hashPrevBlock header field is all zeroes.
Because of its unique role, the first block on every blockchain is given a special name: the Genesis Block.
Block Structure
The block data structure is relatively simple. It usually consists of some metadata and a payload.
The metadata is stored in a section called the block header and usually includes a block timestamp, the unique block hash, the previous block’s hash, the merkle root and several other fields. Each blockchain implementation may add or omit different header fields. The format of block headers is not standardized.
The payload is usually a binary version of the blocks in the same format they travel through the P2P network.
For example, in Bitcoin Core the payload is simply a raw block serialized onto disk storage (written to disk exactly as it travels the network).
Block Size
Blocks can be of any arbitrary size. There is no preset block size or a general standard for block sizes.
From tiny kilobyte sized blocks to several gigabytes large. Some blockchains don’t even limit the block size, allowing for arbitrary size data to be stored.
As always, there’s a trade-off between block size and efficiency. Making blocks too large will require more processing time to compute the signature (hash) of each block. Large blocks also require more transactions to completely fill them.
Data stored in blocks can be simple transaction scripts, such as those stored in Bitcoin Core, smart contracts (as in Ethereum, Tezos and others), files of all kinds, images and even movies (such as the case with Bitcoin SV when used by applications like Twetch).
Therefore, it is convenient to choose appropriately sized blocks to store the kind of data required by each specific application.
E.g. If the expected average entry is just a few bytes large, such as Bitcoin transactions, then blocks can be limited to the megabyte range and still be capable of storing a reasonable amount of entries.
Early on, before the SegWit fork in 2017, Bitcoin had a fixed block size set to 1MB. After SegWit, lots of larger Bitcoin blocks are being mined, some even passing the 2MB size mark. Still, Bitcoin Core blocks do not grow beyond 2MB.
If, on the other hand, a specific application required large binary objects (BLOB’s) to be stored on the blockchain, perhaps a larger block size would be convenient.
Block Storage
Blocks themselves must be stored somewhere on users’ computers.
In Bitcoin Core, and its countless forks, a directory called blocks/ under the data directory will contain data received from the network. This includes the raw blocks and index files designed to quickly access block data.
On Bitcoin Core, each block is stored in regular files and contains all the recently mined Bitcoin transactions from the latest blocks.
Other cryptocurrencies may use different storage systems, such as SQLite or Berkeley databases.
There is no set requirement for block storage, as long as each new block cryptographically references the one before and integrity is guaranteed.
Transactions stored in blocks may be out of chronological order, but blocks themselves are always found in order of insertion. The timestamp marking when the block was mined always increases.
The data stored in blocks, and committed to the blockchain, cannot be tampered with in any way, regardless of how the data is stored on disk.
Any single bit that is changed, in any block in the chain, would change the entire chain signature and allow all other network participants to immediately detect the modification.
Cryptographic Hashing
Every bit of information contained in a blockchain passes through a process known as cryptographic hashing.
This is a secure and well tested process which is peer-reviewed by cryptanalists from around the world. The algorithm is chosen such that it does not result in collisions, when the same hash code is generated for different pieces of information.
Hashing is also performed in a way such that the resulting code cannot be used to recover the originally hashed data. We say that hashing is a one-way process.
Each block will have a signature hash that is universally unique and impossible to reproduce, except if you have knowledge of the original data contained in the block, stored in the exact same order.
That last detail is very important. For instance, if you took the exact same transactions and stored them in a different order within a block, the resulting hash would be different. In this case, even though the block would contain the exact same transaction data, the order with which they’re stored is different and this generates a different signature.
This illustrates how blockchains do not allow any part of the data to be modified, not even the order with which identical data gets stored.
Proof of Knowledge
As we’ve seen, Blockchain is a special kind of database which does not allow any kind of data modification.
Blocks are recorded in chronological order and this order cannot be modified.
Therefore, blockchains prove not only that data is valid, but also at which point in time that data was inserted.
For this reason, Blockchains can be used as “proof of knowledge” of information.
Using a blockchain you can prove that you knew something at a certain point in time. This was used by the creator of Bitcoin itself, when he encoded the following newspaper headline into the very first Bitcoin block ever mined:
The Times 03/Jan/2009 Chancellor on brink of second bailout for banks
The famous headline is a proof of knowledge timestamped January 3 2009.
It proves that Satoshi Nakamoto had access to that piece of information (a newspaper) on that date. The timestamp cannot be modified.
If you wish to prove that you had access to some information at some point in time, all you have to do is hash that information and then store it in a blockchain. In the future all you have to do is publish your original message and its hash so anyone can verify it.
Blockchain in Finance
Financial transactions are naturally well suited to be stored in blockchains.
Money transfers happen chronologically and a secure, often permanent, record must be kept of each operation.
If the order of operations were ever changed, the whole blockchain would be considered tampered with. The amounts involved, as well as other transaction details, are also impossible to tamper with.
This makes the blockchain perfect for digital cash transactions.
Cryptocurrencies
When used in decentralized systems, blockchains enable the kind of cryptocurrencies we now know as Bitcoin, Dogecoin, Cardano ADA and other alternative coins (altcoins).
Bitcoin was the first successful application of blockchain as a storage engine and decentralized financial ledger.
Each Bitcoin block stores transactions in the order a miner used to assemble the block. These transactions are not necessarily in chronological order within the block, but blocks are arranged in chronological order, one after the other.
A block is committed onto the Bitcoin blockchain once per 10 minutes on average. This time period is fixed by the Bitcoin Core source code and cannot be altered.
Since the hash for every new block depends on the hash of the previously newest block, if any piece of data were modified in any earlier block, that change would immediately propagate to the front of the chain. The most recent block hash would suddenly change and the network of verifying nodes would immediately alert users that something unexpected had happened.
Although alternative cryptocurrencies are implemented in several different ways, most of them follow the same basic idea as Bitcoin.
Although second and third generation cryptocurrencies introduce more sophisticated features, such as smart contracts and built-in compliance mechanisms, the basis for the decentralized ledger is still a system of blocks where each block depends on the previous one.
Links
crypto.bi - SHA256(crypto) Inc - Piazza Giordano A147 - 978 - contact@crypto.bi - We love Rome, Italy + Barcelona - 17DAB9EF880DA3BF